





Hoe Microsoft Office 365 en Teams helpt de zorg te verbeteren
Lees hoe een zorginstelling zorg voor patiënten transformeert, kosten bespaart en beter samenwerkt dankzij een innovatief e-health centrum.


Microsoft Nederland
Microsoft Nederland
door Brad Smith, Vicevoorzitter & President van Microsoft
Europa is de thuisbasis van meer dan 200 talen en een rijk cultureel erfgoed dat al duizenden jaren beslaat, bewaard in miljoenen culturele objecten die het verhaal van haar volk vertellen. Maar deze talen zijn meer dan dragers van erfgoed en geschiedenis – ze ondersteunen zowel cultuur als handel door mensen in staat te stellen met elkaar te verbinden, te creëren en zaken te doen.
Toch dreigt een groot deel van Europa’s taalkundige en culturele diversiteit achter te blijven nu de wereld digitaliseert. Het grootste gedeelte van de informatie op het web – de primaire bron van trainingsdata voor de huidige grote taalmodellen (LLM’s) – is in het Engels. Veel daarvan weerspiegelt een Amerikaans perspectief. De Europese Commissie heeft gewaarschuwd dat de ambitie om Europa’s enorme culturele erfgoed te digitaliseren “nog ver buiten bereik ligt.” Europese leiders erkennen dat dit probleem, zonder spoedig ingrijpen, niet alleen cultureel maar ook commercieel van aard is. AI die Europa’s talen, geschiedenis en waarden niet begrijpt, kan haar mensen, bedrijven en toekomst niet optimaal dienen.
Daarom versterken we vandaag in Parijs onze inzet voor Europa’s digitale toekomst met twee nieuwe initiatieven gericht op het toegankelijker maken van wat Europa uniek maakt – haar talen en cultuur. Deze stap bouwt voort op onze European Digital Commitments, die Microsoft eerder dit jaar aankondigde om de AI- en cloudinfrastructuur te versterken, digitale weerbaarheid, privacybescherming en cybersecurity te verbeteren, en de Europese digitale economie te ondersteunen.”
Om de ontwikkeling van meer meertalige LLM’s in en voor Europa te ondersteunen, stationeren we medewerkers van twee van onze innovatiecentra in Straatsburg, Frankrijk. Deze centra dragen bij aan de uitbreiding van meertalige datasets voor AI-ontwikkeling. Met hulp van Microsoft Azure, onze technologische expertise en Europese partnerschappen breiden deze centra meertalige datasets uit om taaldiversiteit beter te laten doorklinken in AI-modellen. In dit kader doen we ook een oproep tot het indienen van voorstellen om de hoeveelheid digitale inhoud in tien Europese talen te vergroten.
Ten tweede breiden we het Culture AI-initiatief van Microsoft uit, om ervoor te zorgen dat de culturele rijkdom van Europa ook in het digitale domein vertegenwoordigd en toegankelijk blijft. Dit initiatief draagt bij aan het behoud van talen, historisch erfgoed en cultureel belangrijke objecten door middel van digitale replica’s en datagedreven samenwerking. Sinds 2019 heeft Microsoft onder meer cultureel erfgoed vastgelegd van Oud-Olympia in Griekenland, de Mont-Saint-Michel in Frankrijk, de Sint-Pietersbasiliek in Rome en de 80e herdenking van de geallieerde landingen in Normandië. Vandaag kondigen we aan dat Microsoft dit najaar, in samenwerking met het Franse Ministerie van Cultuur en het Franse bedrijf Iconem, start met het creëren van een digitale replica van de Notre-Dame in Parijs.
Deze inzet voor Europa’s diversiteit is geen nieuwe missie van Microsoft, maar bouwt voort op meer dan 40 jaar ervaring in het bedienen van landen en culturen in Europa en daarbuiten. Technologie geeft mensen pas echt kracht geeft als het beschikbaar is in de taal die zij spreken. Daarom ondersteunt Windows nu meer dan 90 talen, waaronder alle officiële EU talen en andere talen zoals Baskisch, Catalaans, Galicisch, Luxemburgs, Valenciaans en meer. Ook Microsoft 365 heeft een brede reikwijdte: de Office-toepassingen worden ondersteund in meer dan 30 Europese talen, waaronder alle officiële talen van de Europese Unie.
De urgentie van het dichten van de taalkloof
De Europese Unie kent 24 officiële talen, met daarnaast nog tientallen andere die nationaal of regionaal erkend zijn. Toch vertegenwoordigen veel van deze talen – zelfs enkele van de 24 officiële EU-talen, zoals het Deens, Fins, Zweeds en Grieks – minder dan 0,6% van alle webinhoud. Andere talen, zoals het Maltees, Iers, Ests, Lets en Sloveens, zijn online nauwelijks zichtbaar. Hoewel slechts 5% van de wereldbevolking Engels als eerste taal spreekt, is de helft van alle online content in het Engels, wat het tot de dominante bron van trainingsdata voor AI-modellen maakt

Figuur 1: Common Crawl-inhoud per taal
Deze digitale ondervertegenwoordiging heeft grote gevolgen, aangezien LLM’s sterk afhankelijk zijn van webinhoud voor training. Een taal met een beperkte online aanwezigheid loopt het risico uitgesloten te worden van toekomstige AI-diensten. Grote, algemene modellen kunnen meerdere talen aan, maar missen vaak nuance, culturele context en regionale diepgang. Modellen die getraind zijn op beperkte data zijn minder nauwkeurig, bevatten meer fouten, missen woordenschat en tonen meer bias.[1]
Ter illustratie: Llama 3.1, een populair open source-model, laat een prestatiedaling van meer dan 15 procentpunten zien bij het beantwoorden van vragen in het Grieks ten opzichte van het Engels, en een verschil van meer dan 25 punten tussen Engels en Lets. Als dit model een middelbare scholier zou zijn, zou zij tot de besten van de klas behoren in Engels, gemiddeld scoren in Grieks en onderaan eindigen in Lets. Zulke verschillen tussen talen komen terug in alle belangrijke prestatietests bij de LLM’s.
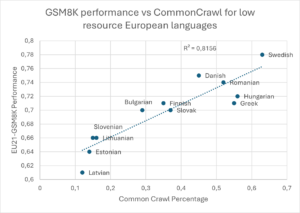
Figuur 2: GSM8K-prestaties versus CommonCrawl voor Europese talen met weinig digitale bronnenError! Bookmark not defined.
In veel gevallen worden talen met een rijke culturele traditie, zoals het Bretons, Occitaans en Reto-Romaans – die door UNESCO als bedreigd worden beschouwd – nauwelijks ondersteund door de huidige gangbare AI-systemen.
De economische waarde van taal
Deze ongelijke ontwikkeling van taalmodellen heeft grote economische gevolgen. Wanneer AI-systemen een regionale taal niet begrijpen of er niet in kunnen reageren, beperkt dat de toegang tot diensten en kansen, en ondermijnt het zowel lokale bedrijven als de bredere economische groei.
De grootschalige inzet van AI wereldwijd zal in het komende decennium een sleutelrol spelen in innovatie en productiviteitsgroei. Net als elektriciteit en andere general-purpose technologieën in het verleden, markeert AI de volgende fase van industrialisatie.
Voor gemeenschappen waarvan de talen online ondervertegenwoordigd zijn, dreigt het risico dat de voordelen van AI onbereikbaar blijven. Stel je een kleine ondernemer voor in Malta die alleen Maltees spreekt. Op dit moment werken geavanceerde AI-tools voor taken als marktanalyse of contentcreatie waarschijnlijk niet in het Maltees, wat zijn mogelijkheden om AI in te zetten beperkt. Of neem een student in een plaats buiten Warschau die alleen Pools spreekt en geen AI-leermaterialen kan vinden in zijn eigen taal, waardoor hij leerachterstand kan oplopen. En zelfs wanneer een AI-platform een taal officieel ondersteunt, kan de gebruikservaring matig zijn.
Europese overheden en instellingen erkennen het belang van deze uitdaging. Om economisch concurrerend te blijven in het AI-tijdperk, moet Europa de taalbarrières doorbreken en de verspreiding van AI op het hele continent stimuleren. Volgens de Europese Commissie maakt slechts 13,5% van de bedrijven in de EU gebruik van AI. Volgens het AI Continent Action Plan van de EU kan het wegnemen van taalbarrières in de interne markt de intra-EU-handel met wel 360 miljard euro stimuleren.
Nieuwe maatregelen om taalkloof te verkleinen
Om deze kloof te helpen dichten, gaat Microsoft samenwerken met Europese partners om de beschikbaarheid van meertalige data te vergroten. In samenwerking met het ICube Laboratory van de Universiteit van Straatsburg – een instelling gericht op engineering, informatica en beeldverwerking – zullen we AI-training ondersteunen met medewerkers van het Microsoft Open Innovation Center (MOIC) en ons AI for Good Lab in Straatsburg, Frankrijk. Dit team wordt ondersteund door een wereldwijd intern netwerk van meer dan 70 Microsoft-engineers, dataspecialisten en beleidsprofessionals. De samenwerking tussen MOIC, het Microsoft AI for Good Lab en de Universiteit van Straatsburg financiert ook twee postdoc-onderzoekers en stelt tot 1 miljoen dollar aan Azure-tegoed beschikbaar.
Dit team begint met het ontsluiten van Microsofts eigen meertalige dataopslag, zodat deze toegankelijk en transparant wordt gemaakt voor het Europese publiek, inclusief open-source developers. Dit omvat bijvoorbeeld meertalige tekstdata van GitHub en spraakdatasets. MOIC en GitHub gaan samenwerken met Hugging Face, een populair samenwerkingsplatform voor AI-modelontwikkeling, om deze data te hosten en breed beschikbaar te maken. Dit bouwt voort op onze bestaande samenwerking met Hugging Face om een breed scala aan open modellen beschikbaar te maken in de Hugging Face model collectie voor 1-klik-deployments via de Azure Model Catalogue. Daaronder valt ook de release van vorige week: het SmoILM3-model – een zeer efficiënt meertalig AI-model met 3 miljard parameters dat zes talen ondersteunt: Engels, Frans, Spaans, Duits, Italiaans en Portugees.
MOIC zal ook samenwerken met Common Crawl, een van de grootste vrije en open repositories van gecrawlde webdata. MOIC financiert werk bij Common Crawl waarbij moedertaalsprekers Europese taaldatasets annoteren en toevoegen aan de openbare Common Crawl-dataset.
Daarnaast zullen MOIC en het AI for Good Lab een oproep doen voor projectvoorstellen om het aanbod van digitale content in tien Europese talen te vergroten door hun tekstverzamelingen op verantwoorde en ethische wijze beschikbaar te stellen voor ontwikkeling van meertalige AI-toepassingen. Aanvragen voor financiering kunnen vanaf 1 september 2025 worden ingediend via de website van het AI for Good Lab. Bij de selectie wordt gekeken naar mogelijkheden om data beschikbaar te maken in talen die online relatief weinig vertegenwoordigd zijn, zoals Ests, Elzassisch, Slowaaks, Grieks en Maltees. De financiering omvat Azure credits en technische ondersteuning door engineers.
Hoewel meer meertalige data essentieel is, kunnen betere technologische tools en expertise ook veel verschil maken. Veel talen gebruiken namelijk schriften die niet goed aansluiten op AI-modellen die zijn gebouwd rond het Latijnse alfabet, en dat levert problemen op. Het Cyrillische schrift, het Griekse alfabet en het Arabische cursieve schrift hebben elk hun eigen kenmerken. Standaard ‘tokenizers’ breken deze schriften vaak op een manier die suboptimaal is. Dit kan het vermogen van een model aantasten om context te begrijpen of spelling correct te verwerken in deze talen. Nieuwe technieken waarmee een model alle schriften uniform kan verwerken, bieden uitkomst. Ook betere mechanismen voor het maken van synthetische data en het verwerken en cureren van die data, met oog voor privacy en gevoelige informatie, kunnen hierbij helpen.
Het MOIC en het AI for Good Lab zullen samenwerken aan het ontwikkelen en delen van kennis, tools en expertise om deze uitdagingen aan te pakken en Europese developers te ondersteunen. Het AI for Good Lab zal een blauwdruk publiceren waarin staat hoe je hoogwaardige taaldatasets kunt opbouwen en lokale LLM’s kunt trainen om meer waarde te halen uit de bestaande data. Beide teams zullen ook relevant onderzoek ondersteunen, bijeenkomsten organiseren, meefinancieren in data commons-projecten, en ervoor zorgen dat kennis, tools en vaardigheden beschikbaar komen waar ze het hardst nodig zijn. Ze blijven ook ondersteuning bieden aan initiatieven zoals die van het Barcelona Supercomputing Center, het Basque Center for Language Technology en de Universiteit van Santiago de Compostela, om AI-modellen getraind in het Spaans, Catalaans, Baskisch en Galicisch beschikbaar te maken via Azure AI Foundry. Deze modellen helpen developers bij het bouwen van AI-toepassingen in de officiële talen van Spanje, wat innovatie en inclusiviteit bevordert.
Tot slot start Microsoft twee nieuwe academische samenwerkingen in Europa om verantwoord AI-onderzoek te stimuleren en de taalkloof te verkleinen. Deze vinden plaats aan de Universiteit van Straatsburg en aan de IE University School of Science & Technology in Spanje. Het AI for Good Lab en het Microsoft Open Innovation Center (MOIC) gaan samenwerken met de Universiteit van Straatsburg en stellen Azure-tegoeden beschikbaar ter ondersteuning van gezamenlijk AI-onderzoek. Aan de IE University School of Science & Technology verstrekt het AI for Good Lab eveneens Azure credits voor gezamenlijk onderzoek dat zich richt op zogenoemde ‘low-resource’-talen, inclusief steun voor bijbehorende afstudeerprojecten om nieuwe oplossingen op het snijvlak van taal en AI te versnellen.
Nieuwe stappen om Europa’s cultureel erfgoed digitaal te beschermen
Sinds 2019 richt het Culture AI-initiatief van Microsoft zich op het gebruik van kunstmatige intelligentie om wereldwijd de talen, plaatsen, verhalen en objecten te behouden die deel uitmaken van het menselijk erfgoed. Het programma, ondersteund door het AI for Good Lab en partners uit de non-profitsector, wetenschap en overheid, helpt bij het digitaliseren en behouden van cultureel erfgoed – van bedreigde talen tot iconische monumenten in bijvoorbeeld Frankrijk, Rome en Griekenland. Of het nu gaat om het maken van digitale replica’s van historische locaties of het toegankelijk maken van museumcollecties, het doel is om culturele identiteit en diversiteit niet alleen te behouden, maar inclusiever en beter vindbaar te maken in het digitale tijdperk.
Vandaag kondigen we ons volgende project aan: de bouw van een digitale replica van de Notre-Dame in Parijs, in samenwerking met het Franse ministerie van Cultuur en het Franse bedrijf Iconem. Het project zal een digital twin creëren van de Notre-Dame, het architectonisch en cultureel icoon dat over de eeuwen is gevormd. De bouw van de Notre-Dame begon in 1163 en duurde bijna 200 jaar. Het resultaat was een 128 meter lang gotisch meesterwerk met twee torens van elk 69 meter hoog. Na de verwoestende brand in 2019 is de Notre-Dame eind 2024 opnieuw geopend voor het publiek. Het project maakt gebruik van technologieën en methoden die we samen met Iconem ontwikkelden bij het creëren van een digital twin van de Sint-Pietersbasiliek vorig jaar, gebaseerd op meer dan 400.000 foto’s en geavanceerde AI-algoritmes, in samenwerking met het Vaticaan.
Net zoals het project van vorig jaar dat elk detail van de Sint-Pieter voor het Vaticaan heeft vastgelegd, zal dit nieuwe project een digitale replica creëren waarin elk detail van de Notre-Dame permanent digitaal wordt bewaard, zodat haar structuur, geschiedenis en symboliek ook voor toekomstige generaties beschermd en toegankelijk blijven. Door geavanceerde beeldtechnologie te combineren met AI, maken we een digital twin die we zullen schenken aan de Franse staat en die in de toekomst te zien zal zijn in het Musée Notre-Dame de Paris.
Naast het project bij de Notre-Dame kondigen we vandaag ook een samenwerking aan met de Bibliothèque Nationale de France en Iconem om bijna 1.500 schaalmodellen van decors van voorstellingen in de Opéra National de Paris (1800–1914) te digitaliseren. De gedigitaliseerde decors worden beschikbaar gesteld via interactieve educatieve ervaringen en tentoonstellingen, en als dataset op het Gallica-platform van de Bibliothèque Nationale de France voor culturele AI- en onderzoeksprojecten.
Tot slot starten we een nieuw project met het Musée des Arts Décoratifs om circa 1,5 miljoen digitale beschrijvingen van objecten openbaar toegankelijk te maken. Dit maakt het voor onderzoekers op het gebied van geschiedenis, kunstgeschiedenis en conservering mogelijk om deze informatie te gebruiken in hun eigen AI-gedreven onderzoeksprojecten.
Vooruitblik: werken vanuit principes
We zetten deze stappen met nederigheid en respect, en erkennen dat het behoud van Europa’s taalkundige en culturele diversiteit een taak is die door Europeanen moet worden geleid. De Europese Unie heeft al een samenwerkingsverband opgezet om taaldatasets te bundelen en cultureel erfgoed te digitaliseren. Onze rol is om deze en soortgelijke inspanningen te ondersteunen. Geen van de aankondigingen van vandaag leidt tot eigendomsrechten op data of technologie voor Microsoft zelf.
De beste manier om meer mensen in Europa in staat te stellen deze uitdagingen aan te pakken, is door hen te voorzien van de AI-vaardigheden die hen succesvol maken in deze domeinen. Zoals de Europese Commissie recent concludeerde, belemmert een gebrek aan digitale vaardigheden in de cultuursector de digitalisering van erfgoed in Europa. Om deze kloof te helpen dichten, zullen MOIC en het AI for Good Lab hun kennis en geleerde lessen delen over hoe dit belangrijke werk goed kan worden uitgevoerd.
Technologie moet de rijkdom van de mensheid weerspiegelen – niet uitwissen. Door nu bewust actie te ondernemen, kunnen we ervoor zorgen dat AI niet leidt tot verlies van taal- en cultuurdiversiteit, maar deze juist versterkt.
Dit is een van de belangrijkste gelijkheidsuitdagingen van het AI-tijdperk. En als we samenwerken – met doelgerichtheid en urgentie – kunnen we de kloof dichten en bouwen aan een digitale toekomst die eer doet aan elke taal, elke cultuur en elke gemeenschap in Europa.
###
Tabel 1:[4]
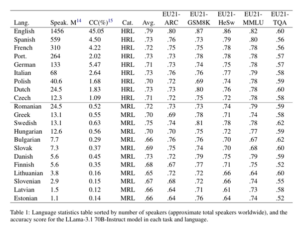
Tabel 1 uit de studie van Thellmann et al. geeft een overzicht van Europese talen, samen met het aantal sprekers, het aandeel webinhoud per taal en de prestaties van het AI-model op vijf verschillende taken.
[1] P. Rohera, C. Ginimav, G. Sawant, and R. Joshi, “Better To Ask in English? Evaluating Factual Accuracy of Multilingual LLMs in English and Low-Resource Languages,” Apr. 28, 2025, arXiv: arXiv:2504.20022. doi: 10.48550/arXiv.2504.20022.
Lees hoe een zorginstelling zorg voor patiënten transformeert, kosten bespaart en beter samenwerkt dankzij een innovatief e-health centrum.
Microsoft Nederland
Microsoft Nederland

De Nederlandse economie blijft groeien, maar ons huidige werkmodel begint zijn grenzen te bereiken. We staan voor een fundamentele uitdaging: de arbeidsproductiviteit moet fors omhoog, maar de mensen om dat mogelijk te maken zijn er simpelweg niet. In vrijwel elke sector kampen organisaties met personeelstekorten, terwijl de druk om efficiënter, slimmer en sneller te werken […]

Paul Honout
Business Group Lead Modern Work, Security & Surface

Ontdek met deze gepersonaliseerde workshops hoe jij je werkplek transformeert De afgelopen jaren is er veel veranderd. Bedrijven gingen van dagelijks samenwerken op kantoor, naar vergaderen en samenwerken op afstand. Werkplekken zien er anno 2021 heel anders uit en het is de vraag of we ooit teruggaan naar de oude manier van werken. Daarom moet je nu jouw werkplekken anders en toekomstgericht inrichten! Hoe benut je de volledige mogelijkheden […]
Microsoft Nederland
Microsoft Nederland
