
Nyenrode Business University: Kobler sammen datakilder på en enhetlig måte
Nyenrode Business University var i gang med å integrere et nytt SaaS-basert økonomisystem da de skjønte at prosessen med å […]
 Pulse
Pulse


Xiaopeng Li
Cloud & AI Business Lead
Give us your feedback!
Worry not if you missed it! We have the event recorded and ready for you to play back on demand!
In this local break-out session of Microsoft Ignite we gathered some MLOps experts from both Microsoft and our fantastic partners and customers in Norway. We had a panel discussion on what is MLOps (Machine Learning Operations), why MLOps matters and shared some key learnings and best practices from their first hand experiences taking ML from PoC to Production on Azure.
The panel consisted of these brilliant folks

Q: What would you say is the hardest step in adopting MLOps?
You know data science projects start with the business problem and delivering an ML model to production involves many different steps. ML code is just small part of the bigger picture and E2E solution. We need to spend most of the time in configurations, data collection, data verification, feature extraction, data wrangling, monitoring, resource managements and managing software packages. It means we should take the time beforehand to get a clear picture of how complex an ML project can be, and this understanding is key in adopting ML Ops. I think understanding and designing a bunch of different workflows in the beginning of the project can be somehow challenging.
(by Shoresh Khezri)
Q: How do you manage to deploy models in Windows docker container for local deployment using Azure ML Workspace and Azure DevOps?
When deploying a model locally this tends to be for debugging and quick iteration of models, so in this situation we would be using a codebase that is held within Azure DevOps and pull down the model we want to deploy locally from the Azure ML Workspace. Once this model is pulled down from the workspace we can deploy it locally using the Azure ML SDK. A very comprehensive overview of this process can be found in the documentation here.
(by Stephen Allwright)
Q: What is your experience with implementing ML Ops with CI/CD (Azure DevOps) and which steps cannot be automated?
On a recent NLP (Natural Language Processing) project we used the reference implementation of the Python MLOps reference architecture on Azure as a starting point, and although the solution has quite a few moving parts we were very happy with the end result. Combining Azure DevOps Pipelines (which are very similar to GitHub Actions) with Azure Machine Learning (AML) and Azure Kubernetes Service (AKS) gave us the automation, storage, compute and hosting we needed to get proper CI/CD in place for the project solution. Being able to simply push a change in the project code to the repository and then, after getting a cup of coffee, see that:
– The code is now tested and validated
– Updated data has been loaded into a new, cleaned and validated dataset
– A new model has been trained and validated
is really satisfying. Then, after a click on the «approve» button, the new model is deployed to Kubernetes and is serving incoming requests. This level of automation has allowed us to avoid a lot of bugs and errors involved in manual and repetitive steps, bringing the best of traditional DevOps into our ML projects.
I believe that most of the steps involved in CI/CD can be automated these days, but we have repeatedly seen that some model and data validation steps can be hard to automate. This is especially true in the development phase, where we are still making significant changes to the model and data processing. When these parts are stable (and model updates are limited to data updates) it is usually possible to introduce full automation as long as approval gates are used at the most critical steps.
(by Øyvind Hetland)
Q: What are the very first steps to take towards practicing MLOps? What are the minimal prerequisites to make MLOps a success?
MLOps brings together people, process, and platform, so they are key elements. There are many jobs and tools involved in production ML. we need data scientists, data engineers and ML engineers in the project also these job definitions don’t use the same tools. So, we need proper tools/platforms and infrastructure to create automated lifecycle where you have got your data engineering pipeline, your ml pipeline and release pipeline. We need CI/CD framework to build, test and deploy software for reproducibility, security, monitoring and code/data/model version control. For example, the combination of Azure DevOps and Azure Machine Learning would be minimal tools prerequisites in Azure to make MLOps a success.
(by Shoresh Khezri)
Q: What is the best approach to implement MLOps from technical point of view?
There are a jungle of good approaches out there, but we’ve had good experience using Azure DevOps Pipelines as the MLOps backbone. These pipelines are written in YAML format and are kept under version control, and are flexible enough to do everything we need to get done. In the project I mentioned earlier, that would be to:
– Execute Terraform for IAC (Infrastructure As Code), so that the pipelines also manage all Azure resources in the project including Kubernetes
– Execute CLI commands to control data flow using Azure Data Factory and Azure Batch
– Control and instruct AML (Azure Machine Learning) using Python scripts that leverage the AML SDK for flexible and scalable compute with/without GPUs
– Package/transform models and deploy them to Kubernetes using Helm and Azure Container Registries (ACR)
– Run tests and wait for manual approval wherever needed
MLOps is, however, more than just CI/CD – it also encompasses the full lifecycle management of a solution and the models that the solutions are built on. We’ve deployed data validation checks and model performance monitoring using a mix of Python libraries and Azure resources, but we have a lot to learn before we can claim to have full control over everything MLOps.
(by Øyvind Hetland)
Q: As part of the MLOps pipelines, what kind of monitoring or metrics could be set up so that an Operations team can better understand if a model is working properly or not?
One important element in monitoring the model in production is the proper exchange of information between the Development and the Operations teams, and having documentation which describes the model intended context, behavior, data requirements and so on. The metrics to be monitored during production are to a large extent context- and application-dependent, so it’s the task of Data Scientists behind the model to determine which performance metrics of the model ought to be monitored for the application at hand. In essence, when it comes to metrics the answer is largely application-dependent. When it comes to monitoring, one monitoring strategy that can be applied upon model release is automated model testing on test data, and to check that the performance of a new model release does not degrade from a previous release. During operations one can monitor model performance if and when the ground-truth will be available at some point after model prediction/inference. Another aspect that may be of interest within monitoring, irrespective of whether the ground truth will become available at a later stage, is data drift. Data drift monitoring essentially checks that the statistical properties of production data are similar to the statistical properties of the training/validation/test datasets. Again, which statistical properties are relevant depend on context and model. The overall distribution of the production data is a property which may be interesting to monitor irrespective of the application.
(by Luca Garrè)
If you have further questions or inquiries, don’t hesitate to get in touch with me via LinkedIn or email (xiaopeng.li@microsoft.com).
Nyenrode Business University var i gang med å integrere et nytt SaaS-basert økonomisystem da de skjønte at prosessen med å […]

Christopher Frenning
National Technology Officer
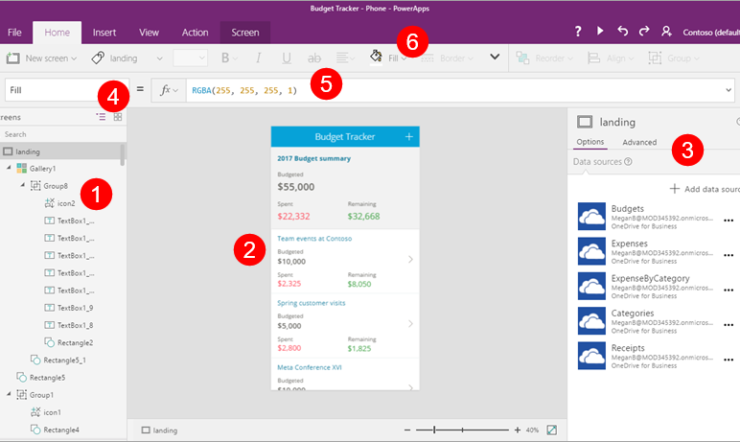
With Power Apps, everyone, no matter their skillset can create innovative business apps to automate and improve processes. Build apps […]

Maxim Salnikov
Developer Engagement Lead